



Remerciements▲
Un grand merci à Viena, Witchounet et stabiloBoss pour leurs corrections et leur patience, à ChristopheJ pour ses critiques constructives et à toute l'équipe Java de developpez.net pour leurs précieuses remarques.
Avant propos▲
La partie Java EE de l'environnement de développement Java est
certainement la plus complexe à
appréhender, de fait, l'extrême diversité des solutions lui
permet une innovation permanente
mais lui donne également une complexité sans précédent. En effet,
contrairement à la plateforme DotNET
la gratuité de la plateforme Java en fait un écosystème très
dynamique, en constante évolution où l'on finit par se perdre.
Quel serveur d'application dois-je utiliser, avec quelle couche
d'accès aux données ?
Sont des questions qui parmi tant d'autres font le cauchemar
des architectes Java EE.
Prenons l'un des piliers de cet environnement (du moins selon les spécifications) : les EJB.
Il est communément admis que la technologie des EJB est très
puissante, mais il l'est tout
autant que leur mise en oeuvre et leur déploiement est très
complexe et ne se justifie
pas la plupart du temps pour des applications "normales".
Un excellent ouvrage traitant de ce thème est "J2EE without EJBs"
par Rod Johnson.
Un autre problème induit par l'utilisation des EJB est la
testabilité, en
effet pour tester une application basée sur Java EE,
il vous
faudra lancer les tests unitaires au sein du conteneur.
Ce qui compte tenu du
temps de démarrage et d'arrêt du conteneur
(le serveur d'application) n'encourage
pas l'écriture des tests unitaires.
Cependant certaines fonctionnalités des serveurs d'application
comme la sécurité,
le mécanisme de transaction ou encore la réutilisabilité des
modules d'entreprise
sont parfois très utiles même si une montée en charge très
importante ou une disponibilité de 99.9% n'est pas indispensable.
C'est à ce niveau que Spring intervient, il permet de faciliter
l'intégration des différentes technologies
qui a priori sont pour le moins hétérogènes. Spring permet
également de fournir certains services que
fournirait un serveur d'application comme par exemple la mise à
disposition d'un objet par RMI, la
gestion des files de messages et des objets qui réagissent
en conséquence ou
encore une gestion de transactions très puissante, tout cela
sans recourir à un serveur d'application.
Cependant dans le cas où cela deviendrait nécessaire,
les différents
services offerts par Spring peuvent s'intégrer dans
un environnement
intégrant un serveur d'applications.
Même si Spring est aussi un conteneur, c'est un
conteneur léger (lighweight container) ce qui permet de l'utiliser
facilement sans avoir besoin de configurer,
d'installer et de maintenir quoi que ce soit.
Enfin il est important de souligner que certaines fonctionnalités
apportées par Spring ne sont tout simplement pas disponible dans
un environnement EJB.
I. Introduction▲
Cet article traite du framework Spring, des concepts
sous-jacents ainsi que de ses applications
et de la façon de les mettre en oeuvre.
Il est organisé de la façon suivante : nous allons tout d'abord
étudier les possibilités
offertes par Spring (Chapitre II), puis quelques cas
d'utilisation (Chapitre III). Ensuite nous
étudierons les concepts et patrons de conception
(design pattern) utilisés
et proposés par Spring (Chapitre IV-V) et enfin nous verrons comment
les mettre en oeuvre
(Chapitre VI-VII) et pour terminer nous parlerons un peu des EJB (Chapitre VIII).
Spring permet d'économiser du code mais surtout
d'augmenter la maintenabilité et la réutilisabilité de vos
composants.
En outre mais c'est une appréciation personnelle le code est
plus clair et plus "propre".
II. Ce que Spring vous apporte▲
Spring est conçu comme une sorte de boîte à outils, au contraire
d'autres frameworks,
il vous laisse libre de n'utiliser que l'un ou l'autre de ses
modules.
Spring est d'ailleurs disponible sous deux formes, celle d'un
jar (librairie Java) unique
et celle de plusieurs fichiers jar permettant de ne rajouter
au projet que la partie
que l'on souhaite utiliser (i.e. Spring Core, Spring Remoting, etc...).
D'autre part Spring fournit non seulement des services de type fonctionnel comme par exemple les transactions mais est également utile d'un point de vue conceptuel en améliorant la qualité du design. Cela par l'utilisation quasi-systématique d'interface.
Spring propose les services suivants (liste non-exhaustive) :
- Découplage des composants. Moins d'interdépendances entre les différents modules.
- Rendre plus aisés les tests des applications complexes c'est-à-dire des applications multicouches.
- Diminuer la quantité de code par l'intégration de frameworks tiers directement dans Spring.
- Permettre de mettre en oeuvre facilement la programmation orientée aspect.
- Un système de transactions au niveau métier qui permet par exemple de faire du "two-phases-commit".
- Un mécanisme de sécurité.
- Pas de dépendances dans le code à l'api Spring lors l'utilisation de l'injection. Ce qui permet de remplacer une couche sans impacter les autres.
- Une implémentation du design pattern MVC
- Un support du protocole RMI. Tant au niveau serveur qu'au niveau du client.
- Déployer et consommer des web-services très facilement.
- Echanger des objets par le protocole http
Ci-dessous un schéma représentant l'organisation des modules et fonctionnalités à l'intérieur du framework.
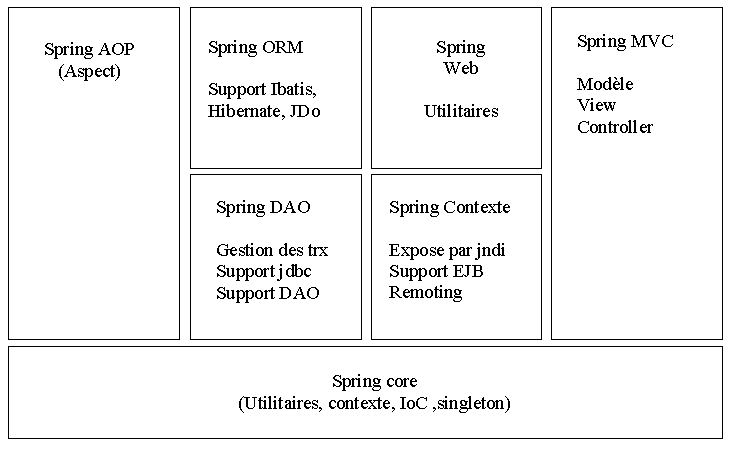
Le framework est organisé en modules, reposant tous sur le module Spring Core:
- Spring Core : implémente notamment le concept d'inversion de contrôle (injection de dépendance). Il est également responsable de la gestion et de la configuration du conteneur.
- Spring Context : Ce module étend Spring Core. Il fournit une sorte de base de données d'objets, permet de charger des ressources (telles que des fichiers de configuration) ou encore la propagation d'évènements et la création de contexte comme par exemple le support de Spring dans un conteneur de Servlet.
- Spring AOP : Permet d'intégrer de la programmation orientée aspect.
- Spring DAO : Ce module permet d'abstraire les accès à la base de données, d'éliminer le code redondant et également d'abstraire les messages d'erreur spécifiques à chaque vendeur. Il fournit en outre une gestion des transactions.
- Spring ORM : Cette partie permet d'intégrer des frameworks de mapping Object/Relationnel tel que Hibernate, JDO ou iBatis avec Spring. La quantité de code économisé par ce package peut être très impressionnante (ouverture, fermeture de session, gestion des erreurs)
- Spring Web : Ensemble d'utilitaires pour les applications web. Par exemple une servlet qui démarre le contexte (le conteneur) au démarrage d'une application web. Permet également d'utiliser des requêtes http de type multipart. C'est aussi ici que se fait l'intégration avec le framework Struts.
- Spring Web MVC : Implémentation du modèle MVC. Personnellement j'utilise plutôt Struts mais c'est surtout une question d'habitude, c'est là la grande force de Spring, rien ne vous oblige à tout utiliser et vous pouvez tout mélanger. Ce qui n'est pas forcément une bonne idée mais nous en reparlerons.
Il est intéressant de jeter un coup d'oeil à l'API, en effet on peut y trouver de nombreuses classes de support, comme par exemple Jasper Reports ou encore de nombreux utilitaires qui le moment venu peuvent vous faire gagner beaucoup de temps.
Citons entre autres utilitaires :
- Des comparateurs : comparateurs inversibles (qui peuvent être ascending ou descending), comparateurs qui s'enchainent, comparateurs qui traitent null comme étant la plus petite valeur, etc…
- Des méthodes utilitaires pour faciliter l'usage de l'arbre DOM
- Un configurateur de fichier log4J pour pouvoir facilement l'intégrer au conteneur.
- Des utilitaires pour le support du framework Quartz (timer) qui permet par exemple d'exécuter un bean comme un cron.
- Et bien d'autres helpers, utilitaires ou intégrateurs.
Entre Spring et l'Apache-Commons vous ne devriez bientôt plus n'avoir qu'à vous concentrer sur le métier.
III. Quand et comment utiliser Spring▲
Voyons à présent différents cas d'utilisation du framework. Ces cas ne sont que quelques exemples, à vous de trouver l'architecture la plus adaptée à vos besoins. Naturellement les variations sont nombreuses, cependant ne soyez pas trop créatifs: pensez à ceux qui vous succéderont et devront faire la maintenance de l'application.
III-a. Architectures▲
Une grande majorité des applications d'entreprise à l'heure actuelle sont basées sur une architecture multicouche (souvent trois). Une couche de présentation (soit une application Internet ou un client lourd), une couche métier (POJO ou EJB) et enfin une couche d'accès aux données. Voici quelques exemples d'architectures :
III-a-1. Application Web Inter/Intranet▲
Voici certainement l'exemple le plus courant :
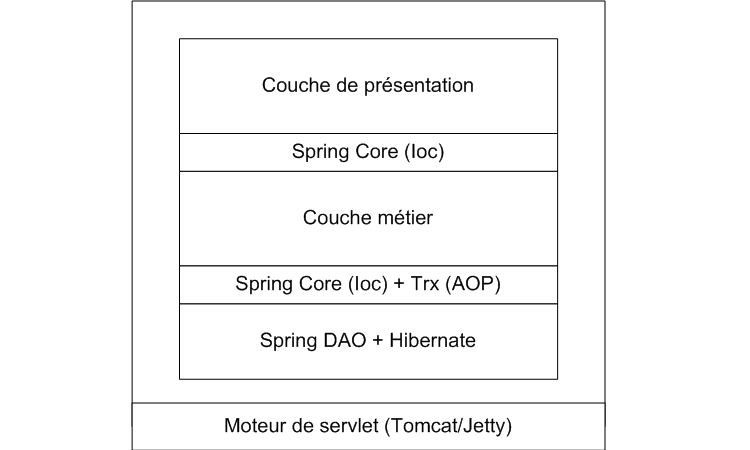
- Une couche de présentation, qui peut être Spring MVC, Struts ou encore WebWork.
- Une couche métier qui en l'occurrence est constituée de POJO (Plain old Java object)
- Une couche d'accès aux données qui peut être JDBC, Hibernate, JDO ou autres.
Entre chaque couche, Spring fait le lien et apporte des fonctionnalités supplémentaires, par exemple :
- sur la couche métier, un mécanisme déclaratif de transactions du type EJB
- ou encore l'utilisation de l'AOP pour activer des logs ou enregistrer les temps de traitements.
- Un mécanisme de templates pour réduire la quantité de code.
III-a-2. Client lourd ou riche▲
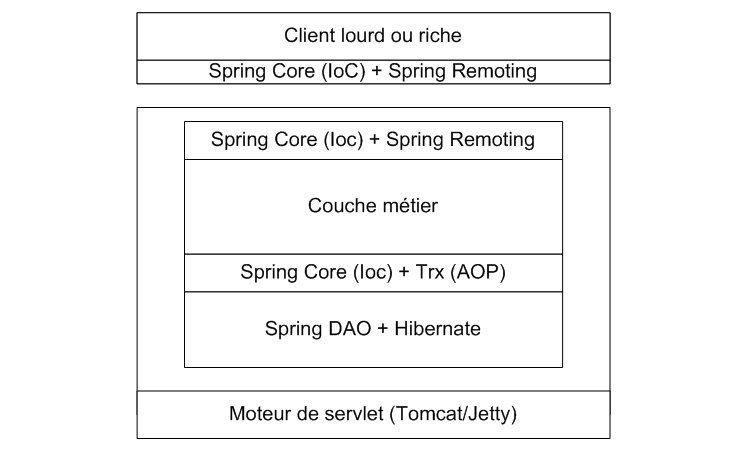
Ce cas de figure reste relativement proche du précédent, c'est là toute la puissance
de Spring et de la programmation par contrat, il suffit de rajouter un ou deux paramètres
et voila nos classes métier précédentes exposées par Web services ou RMI.
Ceci fait, Spring fournit également des outils pour faciliter leurs utilisations sur le
client.
III-a-3. Architecture répartie▲
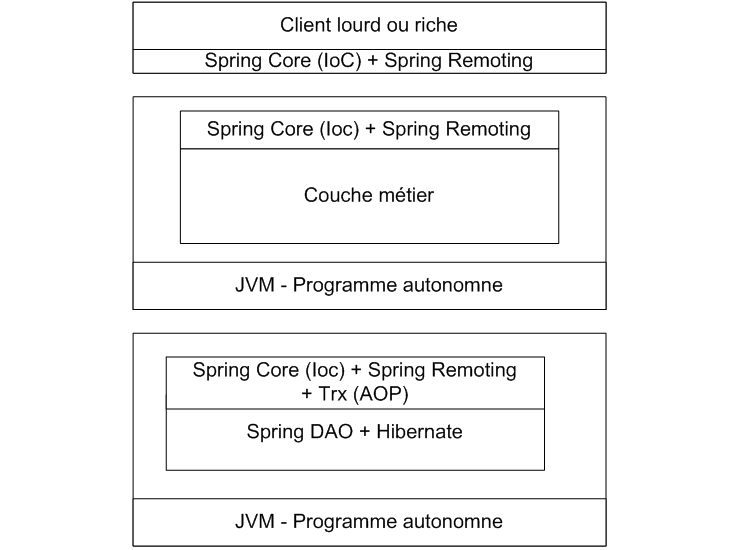
Ce modèle vous permet de réaliser une répartition des modules sur plusieurs JVM et donc
plusieurs serveurs. Même si ce modèle semble équivalent à un serveur d'applications
puisqu'il permet la répartition et même la sécurité des accès et le mécanisme
transactionnel du type JCA, il lui manque l'aspect clustering et partage des sessions.
Nous en rediscuterons dans le chapitre qui présente Spring comme une alternative aux EJB.
III-a-4. EJB gérés par Spring▲

III-a-5. Accès aux EJB d'un serveur d'applications grâce à Spring▲
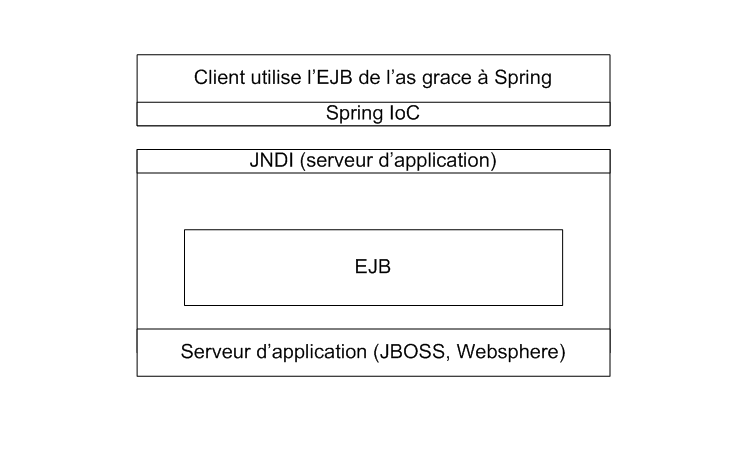
Spring vous permet également d'utiliser des EJB mis à disposition dans un serveur
d'application de façon très simple.
Il existe bien d'autres combinaisons, rien n'empêche les EJB d'utiliser Spring.
La modularité de Spring permet de l'utiliser avec une grande souplesse,
module par module ou tous à la fois.
C'est une sorte de jeu de construction.
b. Exemples de combinaisons, intégration multi framework▲
Spring permet de servir de colle entre différentes technologies et différents frameworks comme par exemple Struts et Hibernate. Pour améliorer la réutilisabilité et accélérer l'implémentation.
IV. La programmation par contrat▲
Les avantages cités précédemment (au chapitre II.) sont les plus évidents, cependant un autre avantage est induit :
Spring oblige à programmer par contrat (interface) et rend la chose praticable. Ce qui présente pour l'architecte un plus non négligeable.
En effet, encore beaucoup d'équipes sont organisées de façon verticale, c'est-à-dire que chaque développeur va réaliser une fonction de A à Z.
Cela présente plusieurs problèmes :
- Tous les développeurs ne peuvent exceller dans tous les domaines. Un bon développeur Web ou Swing n'est pas nécessairement un expert SQL.
- Sauter d'une couche à l'autre et d'une technologie à l'autre induit une perte de temps.
- La parallélisation de certaines tâches s'en trouve diminuée.
- Une tendance à ne pas isoler les couches et à faire du métier dans une action Struts ou dans un listener Swing
Pourquoi cet état de fait ? Parce que pour pouvoir tester une fonction il faut des données,
bref quelque chose à afficher.
C'est là où intervient Spring, comme nous le verrons il permet de changer très facilement
l'implémentation d'une interface et donc de passer aisément d'une pseudo-implémentation
où l'essentiel est codé en dur à l'implémentation faite, une fois celle-ci terminée,
par un collègue ou un tiers.
Voyons les deux modèles :
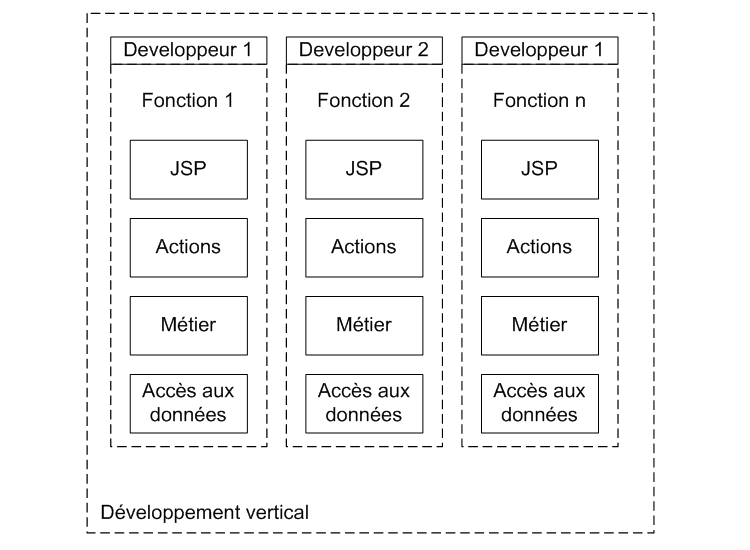
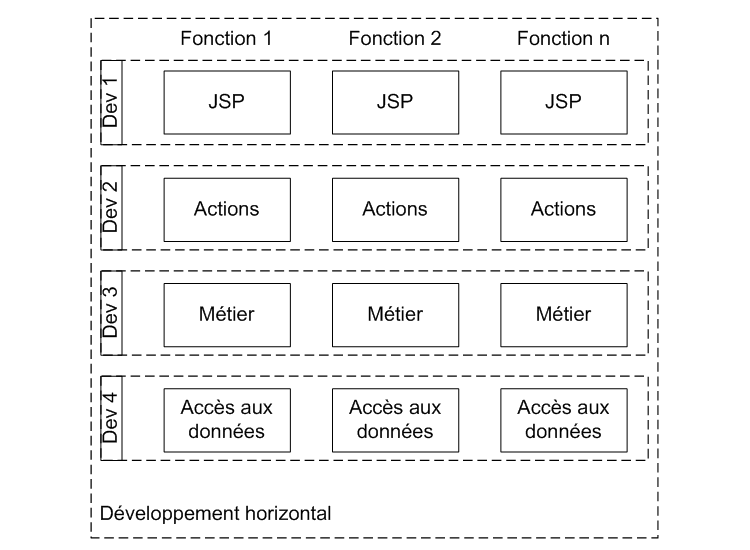
A première vue il faut plus de personnes pour réaliser une application en utilisant la seconde méthode. Il n'est pas possible dans tous les projets de définir un partage des tâches aussi clair. Le tout étant de trouver un compromis entre la productivité et les réalités du projet (expertises des membres de l'équipe, taille du projet, budget, etc.).
Le développement horizontal, c'est-à-dire par couche permet d'améliorer les points suivants :
- Inutile d'avoir des développeurs experts dans l'ensemble des technologies requises.
- Une plus grande réutilisabilité des services du fait de la séparation claire des tâches.
- Moins de bugs, en effet si le programmeur n'est en charge que d'un seul module, il ne peut supposer comment va se comporter le module sous-jacent et doit, de fait mieux protéger son code.
V. Patrons de conception▲
Spring repose sur des concepts éprouvés, patrons de conception et paradigmes,
dont les plus connus sont IoC (Inversion of Control), le singleton, la programmation orientée
Aspect ou encore le modèle de programmation dit " par template ".
Dans ce chapitre nous allons voir la théorie sur laquelle reposent ces modèles de programmation,
si vous êtes déjà familier vous pouvez directement aller au chapitre VI pour voir comment les
mettre en oeuvre.
Insister un peu sur la théorie permettra de plus facilement appréhender la pratique par la suite et éventuellement cela permettra au lecteur d'utiliser ces concepts pour trouver des solutions à ses propres cas pratiques qui ne sont pas couverts ici.
Ces concepts n'étant pas propre à Spring, ils s'appliquent également à d'autres frameworks, je ne prétends en aucun cas établir ici une référence sur les design patterns.
V-a. Le modèle de conception " fabrique " (factory)▲
C'est grâce à ce modèle que Spring peut produire des objets respectant un contrat mais indépendants
de leur implémentation.
En réalité ce modèle est basé sur la notion d'interface et donc de contrat, l'idée est
simplement d'avoir un point d'entrée unique qui permet de produire des instances d'objets.
Tout comme une usine produit plusieurs types de voitures, cette usine a comme caractéristique principale de produire des voitures, de la même façon une fabrique d'objets produira n'importe quel type d'objet pour peu qu'ils respectent le postulat de base. Ce postulat (le contrat) pouvant être très vague ou au contraire très précis.
Voyons le diagramme de classe :

On remarque facilement que le simple fait de changer la méthode getForm() permet de passer d'un formulaire
de type swing à un formulaire de type html.
Cela sans avoir le moindre impact sur tout le code qui en découle.
Nous avons vu ci-dessus que Spring encourageait la programmation par contrat en voici l'une des nombreuses raisons.
Bien entendu aussi longtemps que le programmeur chargé de réaliser la classe SwingForm n'aura pas terminé sa tâche, la méthode getForm() pourra renvoyer une instance d'une pseudo implémentation qui renvoie toujours null ou certaines erreurs remplies en dur pour pouvoir tester et développer les classes clientes.
Naturellement à lui seul ce pattern ne suffit pas, il faudra lui adjoindre le singleton et des possibilités de configuration ainsi que le modèle "bean". Dès lors le pattern IoC (Inversion of contrôle) sera réalisable (Oui je sais je raccourcis).
V-b. Le singleton▲
Il s'agit certainement du patron de conception le plus connu. En effet il est (très) utilisé dans beaucoup de domaines. Ce modèle revient à s'assurer qu'il n'y aura toujours qu'une instance d'une classe donnée qui sera instanciée dans la machine virtuelle.
Les objectifs sont simples:
- Eviter le temps d'instanciation de la classe.
- Eviter la consommation de mémoire inutile.
Ce modèle impose cependant une contrainte d'importance, la classe qui fournit
le service ne doit pas avoir de notion de session. C'est à dire qu'importe le
module appelant, le service réagira toujours de la même façon à
paramètre équivalent, il n'a pas de notion d'historique (ou de session).
Le POJO qui implémentera le service ne doit pas stocker des informations au niveau de l'objet lui-même.
Pour faire simple il ne faut pas modifier les variables membres au sein d'une opération (une méthode du service).
Ce concept relativement simple à appréhender, est également simple à mettre en oeuvre. Du moins en théorie.
Voyons :
L'objectif est de garantir l'unicité de l'instance, pour cela il faut interdire la création
de toute instance en dehors du contrôle de la classe. Dans ce but, nous rendons le
constructeur privé et mettons à disposition une méthode qui retourne une instance de
la classe.

Ce diagramme de classe se traduit par la portion de code suivante:
public class Singleton {
public static Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
private Singleton() {
}
private static Singleton instance;
}En fait il manque quelque chose pour que ce soit une implémentation correcte du singleton.
Il s'agit du problème du multithreading, en effet si plusieurs threads accèdent de façon simultanée
à la méthode getInstance() il se peut que les deux threads détectent en même temps que le membre est null
ce qui conduira à un problème. Pour cela il faudrait déclarer la méthode synchronized ou tout du moins la portion
de code qui manipule l'instance.
C'est justement un des avantages de Spring, vous n'avez plus à vous soucier de cela, Spring le fait et il le fait
très bien.
V-c. IoC: Inversion de contrôle (Inversion of Control), injection de dépendances▲
L'inversion de contrôle (IoC : inversion of control) ou l'injection de dépendances
(Dependency injection) est sans doute le concept central de Spring. Il s'agit d'un "design pattern"
qui a pour objectif de faciliter l'intégration de composants entre eux.
Le concept est basé sur le fait d'inverser la façon dont sont créés les objets.
Dans la plupart des cas si je souhaite créer un objet qui en utilise un autre je programmerai
quelque chose du type :
DBConnexion c=new DBConnexion(" jdbc :….. ") ;
Pool p=new Pool(c);
//reste du code
SecurityDAO securityDao=new SecurityDao(p);
SecurityBusiness securityBusiness=new securityBusiness(securityDao);A présent votre chef de projet, vous dit : "le client a changé d'avis, il souhaite utiliser LDAP et non sa base de données pour l'identification. Donc tout de go, vous changez en :
Properties p=new Properties ("ldap.properties");
LDAPConnexion c=new LDAPConnexion(p) ;
//reste du code
SecurityDAO securityDao=new SecurityDao(c);
SecurityBusiness securityBusiness=new securityBusiness(securityDao);De là, votre chef de projet revient, vous met une tape sur l'épaule, vous remercie
(si si ça existe) et vous dit : bien, ce programme marche très bien, la direction a
décidé d'en faire un produit standard compatible avec toutes les bases de données
et systèmes d'authentification comme Active Directory.
Bon, à présent pour vous ça devient moins drôle.
La solution consiste à bien séparer les couches et à utiliser des interfaces pour se faire.
Naturellement il ne s'agit pas de quelque chose de propre à Spring,
donc dans un premier temps nous aurons :
IConnexion c=new LDAPConnexionImpl () ;
ISecurityDAO securityDao=new LDAPSecurityDaoImpl(c);
ISecurityBusiness securityBusiness=new SecurityBusinessImpl(securityDao);Maintenant le problème qui se pose est celui de la configuration,
comment configurer de manière simple les drivers et les objets nécessaires.
Et surtout comment faire pour que le tout s'intègre proprement dans l'application.
C'est là que l'inversion de contrôle rentre en jeu. L'objectif n'est plus de
fournir un objet à un autre objet mais au contraire de faire en sorte que, l'objet
dont on a besoin, sache lui-même ce dont il a besoin. Et le cas échéant
si un des objets nécessaires a lui-même des dépendances qu'il se débrouille
pour les obtenir. Ce qui devrait résulter en :
ISecurityBusiness securityBusiness=IoCContainer.getBean("ISecurityBean);La méthode getBean est purement formelle pour l'exemple, l'objectif est de montrer
que le code est réduit à sa forme la plus simple, les dépendances étant déclarées
dans la configuration du conteneur.
Mais que fait-elle :
- Elle résout le nom ISecurityBean dans son arbre de dépendances et trouve la classe qui l'implémente
- Elle en crée une instance(cas d'une injection pas mutateurs, nous verrons cela plus tard)
- Crée les objets dépendants et les définit dans l'objet ISecurityBean grâce à ses accesseurs.
- Et enfin, récursivement fait de même pour toutes les dépendances des dépendances etc…
Sur la figure suivante on remarque que les dépendances entre les couches sont réduites au minimum
et que l'on peut facilement remplacer une implémentation par une autre sans mettre en danger la stabilité
et l'intégrité de l'ensemble.
Naturellement la nouvelle implémentation ne doit pas être truffée de bugs.

Il existe trois types d'injection : Les exemples de code fournis ci-après ne sont pas des exemples réels, ils ne sont là que pour donner une idée de la façon dont fonctionne un conteneur capable de résoudre les dépendances d'injection.
- L'injection par constructeurs : Ce type d'injection se fait sur le constructeur, c'est-à-dire que le constructeur dispose de paramètres pour directement initialiser tous les membres de la classe.
Object construitComposant(String pNom){
Class c=rechercheLaClassQuiImplemente(pNom) ;
String[] dep= rechercheLesDependance(pNom) ;
Params[] parametresDeConstructeur;
Pour chaque element (composant) de dep
Faire
Object o= construitComposant(composant) ;
Rajouter o à la liste de parametresDeConstructeur ;
Fin Faire
construireClasse( c, parametresDeConstructeur)
}- L'injection par mutateurs (setters) :
Ce type d'injection se fait après une initialisation à l'aide d'un
constructeur sans paramètre puis les différents champs sont initialisés
grâce à des mutateurs.
composant.setNomMembre(o) : le nom setNomMembre est trouvé grâce à la configuration du composant où il est déclaré que le membre à initialiser est nomMembre. Pour en savoir plus sur la "design pattern bean".
Object construitComposant(String pNom){
Class c=rechercheLaClassQuiImplemente(pNom) ;
Object composanr=new c() ;
String[] dep= rechercheLesDependance(pNom) ;
Params[] parametresDeConstructeur;
Pour chaque element (composant) de dep
Faire
Object o= construitComposant(composant) ;
composant.setNomMembre(o) ;
Fin Faire
}- L'injection d'interface : Cette injection se fait sur la base d'une méthode, elle est plus proche de l'injection par mutateurs, enfin la différence se résume à pouvoir utiliser un autre nom de méthode que ceux du "design pattern bean". Pour cela, il faut utiliser une interface afin de définir le nom de la méthode qui injectera la dépendance.
Object construitComposant(String pNom){
Class c=rechercheLaClassQuiImplemente(pNom) ;
Object composanr=new c() ;
String[] dep= rechercheLesDependance(pNom) ;
Params[] parametresDeConstructeur;
Pour chaque element (composant) de dep
Faire
Object o= construitComposant(composant) ;
composant.méthodeInjection(o) ;
Fin Faire
}composant.méthodeInjection (o) : le nom méthodeInjection est trouvé grâce à la configuration du composant où il est déclaré que la méthode qui injecte l'objet est définie par une interface. Dans notre exemple l'interface serait :
public interface IInjectMethode{
public void méthodeInjection(Object o) ;
}L'implémentation du composant se devra alors naturellement d'implémenter cette interface également.
V-d. Programmation orientée aspect▲
Comme nous pouvons le voir dans la figure suivante, un module ou composant métier est régulièrement pollué par de multiples appels à des composants utilitaires externes.

De fait ces appels rendent le code plus complexe et donc moins lisible. Comme chacun sait,
un code plus court et donc plus clair améliore la qualité et la réutilisabilité.
Cela implique:
- Enchevêtrement du code
- Faible réutilisabilité
- Qualité plus basse due à la complexité du code
- Difficulté à faire évoluer
La solution constituerait donc à externaliser tous les traitements non relatifs à la logique métier en dehors du composant.
Pour ce faire il faut pouvoir définir des traitements de façon déclarative ou programmative sur les points clés de l'algorithme. Typiquement avant ou après une méthode.
Dans la plupart des cas ce genre de traitements utilitaires se fait en début ou en fin de méthode,
comme par exemple journaliser les appels ou encore effectuer un commit ou un rollback sur
une transaction.
La démarche est alors la suivante:
- Décomposition en aspect: Séparer la partie métier de la partie utilitaire.
- Programmation de la partie métier: Se concentrer sur la partie variante.
- Recomposition des aspects: Définition des aspects
Il existe deux types de programmation orientée aspect, ces deux techniques ont chacune des avantages et des inconvénients :
- l'approche statique, c'est-à-dire que la connexion entre l'aspect et la partie métier se fait au moment de la compilation ou après dans une phase de post-production. Par exemple par manipulation du bytecode. Comme toujours cette méthode intrusive n'est pas forcément la plus transparente.
- L'approche dynamique, dans ce cas, la connexion s'effectue par la réflexion donc au moment de l'exécution. Cette méthode bien que plus transparente est naturellement plus lente, mais présente l'avantage de pouvoir être reconfigurée sans recompilation.
A présent il est important de définir le vocabulaire :
| Concept (Francais) | Concept (Anglais) | Description |
|---|---|---|
| Point de jonction | Joinpoint | Endroit dans le code où le conseil (advice) est inséré |
| Coupe ou points d'actions | Pointcut | Ensemble de points de jonction, souvent une expression régulière |
| Conseil ou greffon | Advice | Fragment de code inséré au point de jonction, par exemple une journalisation ou un commit |
| Aspect | Aspect | Ensemble de points de jonction, de conseils et de coupes |
| Tisseur ou trammeur | Weaver | Framework permettant de mettre en place les aspects sur un code métier |
Le problème le plus important induit par la programmation orientée aspect est le manque de
traçabilité en phase de débogage par exemple, sous l'effet de la post-production
certains débogueurs ont beaucoup de mal à, y retrouver leur latin.
Dans le cas de la stratégie dite dynamique les sauts d'un aspect à un autre peuvent dérouter
l'utilisateur non averti.
V-e. Programmation par template▲
L'objet de ce design pattern est de séparer l'invariant d'un procédé de sa partie variante.
Dans Spring les templates sont très utilisés dans le cadre de l'accès aux données et de
la gestion des transactions.
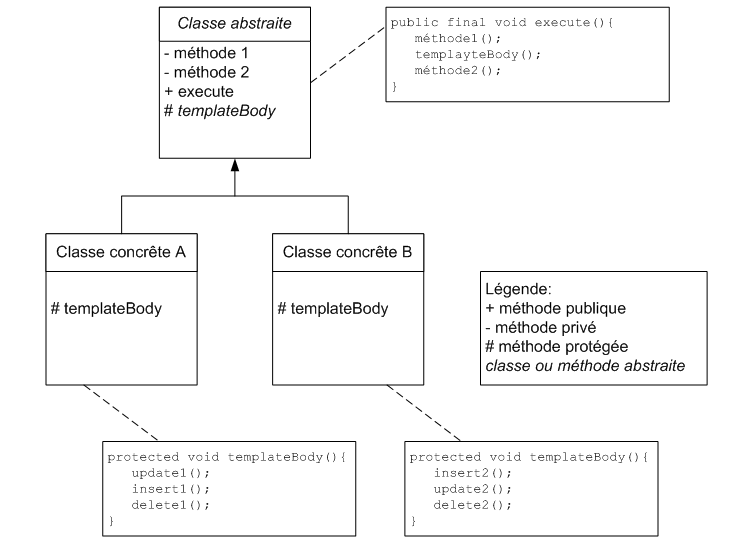
La partie invariante du code est placée dans la partie abstraite de la classe, ainsi toute classe qui
héritera de cette classe abstraite n'aura qu'à implémenter la partie variante.
Voici un exemple d'utilisation du pattern template tiré de la documentation de Spring :
tt.execute(new TransactionCallbackWithoutResult() {
protected void doInTransactionWithoutResult(TransactionStatus status) {
updateOperation1();
updateOperation2();
}
});Voici comment est déclarée cette classe dans Spring :
public abstract class TransactionCallbackWithoutResult
implements TransactionCallback {
public final Object doInTransaction(TransactionStatus status) {
doInTransactionWithoutResult(status);
return null;
}
protected abstract void doInTransactionWithoutResult(TransactionStatus status);
}Ce qui satisfait précisément au schéma de classe déclaré ci-dessus.
La partie variante est implémentée dans la méthode abstraite, en l'occurrence
ce que vous voulez effectuer dans une transaction.
V-f. Le modèle MVC 1 et 2 (Model View Controller)▲
Ce n'est peut-être pas le concept le plus important dans Spring, dans la mesure où il a été largement démocratisé par Struts. Cependant encore trop de programmeurs ont tendance à mélanger toutes les couches, à mettre des traitements métiers dans la jsp, ou encore des servlets dans lesquelles ils mélangent allégrement html, javascript, métier et bien d'autres choses.
Etant donné que l'un des objectifs les plus importants de Spring est la séparation des couches, la partie MVC et le concept d'un point de vue général me semblent indispensables.
Que vous utilisiez Spring, webworks, Struts ou autre chose, peu m'importe du moment que vous sépariez les couches.
Comme cité précédemment l'objectif est de séparer les couches et les technologies. A cette fin, le paradigme se divise en trois parties:
- Le modèle (Model) : C'est la représentation des informations liées spécifiquement au domaine de l'application. C'est un autre nom pour désigner la couche métier. La couche métier ou plutôt la partie qui représente l'information en respectant une structure liée au domaine d'activité, celle qui effectue des calculs ou des traitements amenant une plus value sur l'information brute. Par exemple le calcul du total des taxes sur un prix hors taxe ou encore des vérifications telles que: Y a t-il encore des articles en stock avant d'autoriser une sortie de stock.
- La vue (View) : Cette couche ou ce module effectue le rendu de la couche métier
dans une forme qui est compréhensible par l'homme, par exemple une page html.
Attention souvent le concept MVC est associé à une application web mais ce n'est pas obligatoire: en effet le framework Swing qui permet de produire des interfaces utilisateurs "sous forme de clients lourds" permet également d'implémenter MVC. - Le contrôleur (Controller) : Ce module organise la communication entre les deux premiers. Il invoquera une action dans la couche métier (par exemple récupérer les données d'un client) suite à une action de l'utilisateur (cliquer sur le lien : voir détails du client) et passera cette information à la vue (jsp qui affiche les détails).
La couche d'accès aux données est ignorée ici parce que sous jacente à la couche métier. Alors par pitié cessez de faire appel à vos Data Source dans les jsp ou même dans le contrôleur.
Tout d'abord cela vous permettra de pouvoir debugger et tester plus facilement le code en l'isolant de la partie affichage. En effet la plupart des bugs sont des problèmes avec l'interface donc ce n'est pas la peine de compliquer encore la donne avec des bugs métiers ou d'accès aux données.
De plus le jour où votre patron vous demandera de rendre l'application compatible avec
les téléphones portables vous n'aurez qu'à remplacer la partie Vue par une vue qui
supporte wml par exemple.
Dans la suite de cet exposé je partirai de l'architecture suivante:
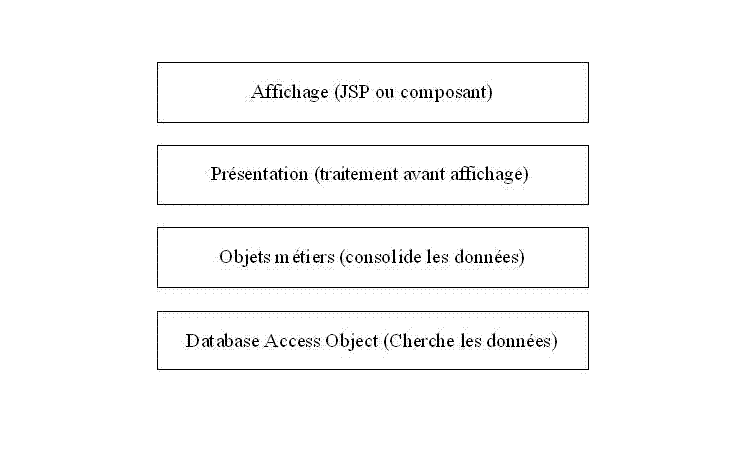
Voyons l'interaction entre les différents composants dans le cadre du type 1.
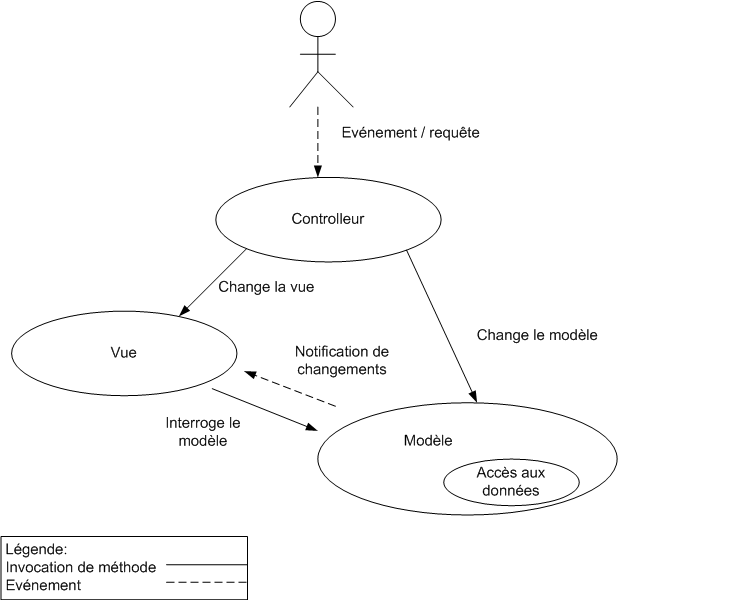
Le problème de ce design pattern est la partie concernant les notifications de changement dans le modèle, en effet si ce point ne pose pas de problème dans le cadre de swing par exemple, où les composants de la vue sont connectés et capables d'intelligence il n'en est pas de même pour les applications web.
Dans le cadre d'une application web c'est le design pattern MVC2 qui est utilisé car il ne nécessite pas l'emploi du design pattern observer (celle qui permet la notification sur les composants) qui observe le modèle et permet à la vue de réagir pour se mettre à jour.
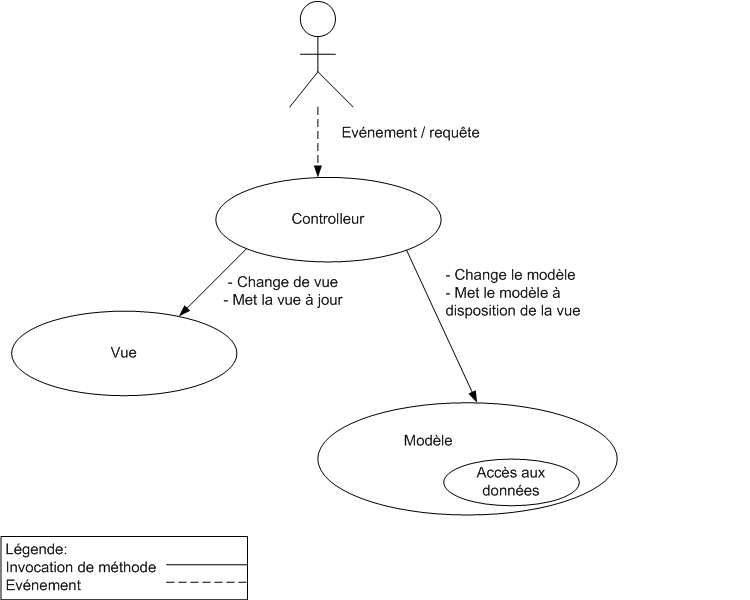
On remarque que c'est le contrôleur qui devient le module central. De fait la vue peut à présent se contenter d'afficher sans aucune intelligence.
Cependant même si le design MVC permet de mieux séparer les couches, il ne faut pas oublier qu'il ne s'agit pas de la façon de procéder la plus intuitive, elle induit donc d'investir du temps dans la réflexion sur la façon de séparer les différentes couches et technologies et surtout de bien réfléchir dans quelle couche s'effectue quel traitement.
De plus les frameworks génèrent souvent plus de fichiers et naturellement plus de configuration. Ce surplus de complexité est cependant bien contrebalancé par la flexibilité supérieure, la plus grande fiabilité, une plus grande facilité pour tester et débugger (puisque que l'on peut tester les bouts un à un).
V-g. La convention bean▲
C'est grâce à cette convention que Spring va pouvoir effectuer l'injection. En effet dans le fichier de configuration seul le nom de la propriété est connu. Or les propriétés se doivent d'être privées pour garder la cohérence du comportement de l'objet.
Pour qu'une classe soit compatible avec la convention JavaBean il faut :
- Que la class soit sérialisable (implements Serializable). Pour pouvoir être persistée.
- Avoir un constructeur sans arguments (constructeur par défaut).
- Ses propriétés doivent être accessibles par des accesseurs (getters et setters) selon la convention set"Nom de l'attribut" et get"Nom de l'attribut".
Voici un exemple de service suivant la convention JavaBean :
/**
* L'instance du dao sera injecté par Spring
* lors de l'initialisation du service.
*/
IStockDAO mStockDao = null;
/**
* @see net.zekey.interfaces.business.IStockService#sortArticleDuStock(java.lang.String, int)
*/
public void sortArticleDuStock(String pArticleId, int pQty)
throws ArticleNotFoundException,
QtyNegativeException,
NotEnoughArticleInStockException {
...
}
/**
* @see net.zekey.interfaces.business.IStockService#getQtyEnStock(java.lang.String)
*/
public int getQtyEnStock(String pArticleId) throws ArticleNotFoundException {
....
return mStockDao.getQtyEnStock(pArticleId);
}
/**
* @return Retourne le stockDao
*/
public IStockDAO getStockDao() {
return mStockDao;
}
/**
* @param pStockDao Définie le stockDao.
*/
public void setStockDao(IStockDAO pStockDao) {
mStockDao = pStockDao;
}
}VI. La pratique : exemples concrets d'utilisation▲
VI-a. Découplage des couches (IoC, Template)▲
Le découplage des couches s'effectue en diminuant autant que faire se peut les dépendances
et les appels entre couches.
En effet plus l'imbrication entre ces modules est grande plus il est difficile de
tester les modules.
Prenons un exemple, vous êtes chargé de réaliser une application qui gère des articles.
Il vous faut réaliser une fonction qui sort un ou plusieurs articles du stock.
public class Stock{
void sortArticleDuStock(String pArticleId, int pQty,
java.sql.Connection pConn){
try{
String sql ="update Articles a set a.qty=a.qty-" +
pQty + " where a.articleId='" + pArticleId + "'";
Statement statement=pConn.createStatement();
statement.executeStatement(sql);
} catch(Exception e){
e.printStackTrace();
}finally{
if(statement != null){
try{
statement.close();
}catch(Exception ex){
ex.printStackTrace();
}
}
}
}
}Cette méthode fait son travail, c'est-à-dire déduire une quantité du stock.
Le problème se situe au niveau de la maintenabilité et également de la testabilité.
Vous vous rendez compte que le code ci-dessus n'est pas très résistant
aux mauvais traitements.
C'est à dire que si l'utilisateur fournit un article qui n'existe pas il ne se passe rien.
De plus si la quantité est négative et bien on rajoutera des articles
(certes vous pourrez toujours essayer de vendre ça comme une fonctionnalité :-D).
Plein de remords vous améliorez la classe. Après avoir modifié le code vous obtenez quelque chose du genre :
public class Stock{
void sortArticleDuStock(String pArticleId, int pQty,
java.sql.Connection pConn) throws ArticleNotFoundExeception,
QtyNegativeException(){
try{
if(pQty<0){
thrown new QtyNegativeException();
}
sql ="select 'x' from Articles a where a.articleId='" +
pArticleId + "'";
Statement statement=pConn.createStatement();
Resultset resultSet=statement.executeQuery(sql);
if(resultSet==null ¦¦ !resultSet.next()){
thrown new ArticleNotFoundException();
}
String sql ="update Articles a set a.qty=a.qty-" +
pQty + " where a.articleId='" + pArticleId + "'";
statement=pConn.createStatement();
statement.executeStatement(sql);
} catch(SQLException e){
e.printStackTrace();
}finally{
if(statement != null){
try{
statement.close();
}catch(SQLException ex){
ex.printStackTrace();
}
}
}
}
}Ce code va devenir rapidement ingérable. Tout d'abord tout y est mélangé,
la partie métier et la partie accès aux données, ce qui est difficilement
lisible et le moindre changement impose de tout re-tester.
De plus si le projet devient urgent, impossible de paralléliser le travail.
Et la granularité des tests unitaires est pour le moins mauvaise.
Maintenant si votre équipe décide en réunion qu'il va falloir gérer plus d'une entreprise,
(parce que le commercial a eu une idée brillante) je vous laisse imaginer les changements.
Il faudra en l'occurrence changer les signatures des méthodes pour soit rajouter
un paramètre soit englober les paramètres dans un objet.
Je ne parle même pas des problèmes si vous décidez de remplacer l'accès
aux données par Hibernate ou Jdo en lieu et place du SQL.
Maintenant voyons le code suivant :
class StockBusiness{
StockDao mDao;
public StockBusiness(){
StockDao mDao=new StockDao();
}
void sortArticleDuStock(String pArticleId, int pQty)
throws ArticleNotFoundExeception, QtyNegativeException(){
try{
if(pQty<0){
thrown new QtyNegativeException();
}
if(!stockDao.articleExist(pArticleId)){
thrown new ArticleNotFoundException();
}
mDao.sortArticleDuStock(pArticleId, pQty);
}
}
} class StockDAO{
DriverManagerDataSource mDataSource;
public StockDao(){
DriverManagerDataSource dataSource = new DriverManagerDataSource();
dataSource.setDriverClassName( "org.hsqldb.jdbcDriver");
dataSource.setUrl( "jdbc:hsqldb:hsql://localhost:");
dataSource.setUsername( "sa");
dataSource.setPassword( "");
}
boolean articleExist(String pArticleId){
boolean ret=true ;
Resultset resultSet=null;
Statement statement=null;
try{
sql ="select 'x' from Articles a where a.articleId='" +
pArticleId+"'";
statement= mDataSource.getConnection().createStatement();
resultSet=statement.executeQuery(sql);
if(resultSet==null ¦¦ !resultSet.next()){
ret=false;
}
}catch(JDBCException e){
e.printStackTrace();
}finaly{
try{
resultSet.close();
}catch(JDBCException ex1){
ex1.printStackTrace();
}finally{
try{
statement.close();
}catch(JDBCException e2){
e2.printStackTrace();
}
}
}
}
void sortArticleDuStock(String pArticleId, int pQty){
Statement statement=null;
try{
String sql ="update Articles a set a.qty=a.qty-" + pQty +
" where a.articleId='" + pArticleId + "'";
statement= mDataSource.getConnection().createStatement();
statement.executeStatement(sql);
} catch(SQLException e){
e.printStackTrace();
}finally{
if(statement != null){
try{
statement.close();
}catch(SQLException ex){
ex.printStackTrace();
}
}
}
}
}Le code précédent est plus long mais présente plusieurs avantages : tout d'abord
il est plus réutilisable puisque la méthode articleExist() de la classe StockDao
est utilisable depuis d'autres méthodes.
Ensuite le code est nettement plus lisible.
Sans utiliser Spring on peut encore améliorer la chose
en introduisant la notion de programmation par contrat.
C'est-à-dire que nous définirons 2 interfaces, une pour la classe métier et
une pour la couche d'accès aux données.
public interface IStockBusiness{
void sortArticleDuStock(String pArticleId, int pQty)
throws ArticleNotFoundExeception, QtyNegativeException();
} public interface IStockDao{
void sortArticleDuStock(String pArticleId, int pQty);
boolean ArticleExist(String pArticleId);
}Dès lors le programmeur de la couche métier peut prévoir une pseudo-implémentation
pour tester sa partie sans pour autant que la couche d'accès aux données
ne soit terminée.
Cette possibilité bien que souvent sous-estimée permet de rapidement
créer des vues pour que le client ait une idée très proche de la réalité de ce que
sera son produit, sans pour autant devoir jeter le prototype après utilisation.
Bien sûr peu lui importe également de savoir que la couche de données soit
implémentée avec Hibernate ou avec JDO ou encore JDBC.
Le seul endroit où le code est encore dépendant de la couche inférieure
se trouve dans les constructeurs.
A présent voyons en quoi Spring peut nous aider :
Spring se configure grâce (entre autres) à un fichier XML, ce fichier se trouvera en principe à la racine du répertoire classes :
class StockDAO implements IStockDao extend JdbcDaoSupport{
DataSource mDataSource;
public setDataSource(DataSource pDataSource){
mDataSource=pDataSource;
}
boolean articleExist(String pArticleId){
String sql = "select count(*) from Articles a where a.articleId='" +
pArticleId + "'";
int count = jt.queryForInt(sql);
return count > 0 ? true : false;
}
void sortArticleDuStock(String pArticleId, int pQty){
String sql = "update Articles a set a.qty=a.qty-" + pQty +
" where a.articleId=' + pArticleId + "'";
getJdbcTemplate().execute(sql);
}
} class StockBusiness implement IStockBusiness{
IStockDao mDao;
public setDao(IStockDao pDao){
mDao=pDao;
}
void sortArticleDuStock(String pArticleId, int pQty)
throws ArticleNotFoundExeception, QtyNegativeException(){
if(pQty<0){
thrown new QtyNegativeException();
}
if(!stockDao.articleExist(pArticleId)){
thrown new ArticleNotFoundException();
}
mDao.sortArticleDuStock();
}
boolean articleExist(String pArticleId){
return mDao.articleExist(pArticleId);
}
} <?xml version="1.0" encoding="UTF-8"?>
<beans>
<bean id="prodDataSource"
class="org.apache.commons.dbcp.BasicDataSource">
<property name="driverClassName">
<value>org.postgresql.Driver</value>
</property>
<property name="url">
<value>jdbc:postgresql://localhost:5432/prod</value>
</property>
<property name="username"><value>prod</value></property>
<property name="password"><value>toto</value></property>
</bean>
<bean id="stockDao" class="StockDao">
<property name="dataSource">
<ref local="prodDataSource"/>
</property>
</bean>
<bean id="stockBusiness" class="StockBusiness">
<property name="dao">
<ref local="stockDao"/>
</property>
</bean>
</beans>Analysons ce code, tout d'abord la partie métier :
- Pas de changement majeur
- Ajout d'un mutateur (setDao) qui respecte la convention de nommage des Java Beans.
En effet c'est selon cette norme que Spring trouve le mutateur qui lui permet d'initialiser un objet après l'avoir créé.
La classe StockDao :
- Enormément simplifiée grâce à l'utilisation du pattern template
(JDBCTemplate) qui permet d'abstraire toute la partie gestion des exceptions,
ouverture et fermeture des connexions, sessions et autres resultset ou statement.
Nous parlerons de façon plus détaillée de JdbcTemplate dans la suite de ce document. - Ajout d'un mutateur pour que Spring puisse initialiser le Data Source de cette classe après la création.
Le fichier Spring.xml : Voici un fichier spring.xml minimaliste
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE beans PUBLIC "-//SPRING//DTD BEAN//EN"
"http://www.springframework.org/dtd/spring-beans.dtd">
<beans>
</beans>Le premier bean qui est déclaré gère le data source est a pour nom prodDataSource.
On remarque que différents paramètres de configuration de l'objet peuvent être
déclarés dans le fichier de configuration.
Chaque propriété (property) correspond à un mutateur (setter) de la forme setProperty.
La valeur (value) lui sera injectée. Il s'agit ici d'une inversion de contrôle ou
dépendance d'injection de type injection par mutateur.
Le second bean déclare le DAO. On peut remarquer que ce n'est pas une valeur qui
lui est injectée mais une référence (ref) c'est à dire un objet préalablement
créé ou encore à créer par Spring.
C'est là que commence l'injection de dépendances puisque c'est l'objet qui a connaissance de
ce dont il a besoin et que c'est le conteneur (Spring) qui crée et injecte les dépendances.
" local " signifie que l'objet en question est présent dans le fichier XML
courant et donc que le parseur XML peut en valider le nom.
A noter que Spring peut également effectuer les résolutions automatiquement,
c'est à dire qu'il n'est pas nécessaire de donner le nom du bean à référencer (i.e : <ref local="prodDataSource"/>)
Si la référence est omise Spring essayera de trouver un bean de type correspondant en l'occurrence un bean de type DataSource(autowire by type) ou
par le nom de l'attribut (property name="dataSource") dans ce cas Spring cherche un bean avec pour nom dataSource (autowire by name).
Vous pouvez aussi injecter des types simples directement tels que des listes, des map ou encore les wrappers des types primitifs.
Par rapport au code d'origine celui-ci n'est pas beaucoup plus court puisque le gain amené par l'utilisation du JDBC template est consommé par le fichier XML de configuration ainsi que le partage en plusieurs classes et interfaces.
Mais la multiplication des méthodes dans la couche d'accès aux données
finirait par produire un gain non négligeable
en terme de ligne de code et donc en qualité.
De plus le code est vraiment beaucoup plus clair et une éventuelle
modification en sera très fortement simplifiée.
VI-b. Tests (IoC)▲
A première vue pas grand-chose à dire puisque l'objectif même de l'injection de
dépendance et donc de Spring est de découpler le logiciel de son conteneur. Et les
services de leur implémentation.
De ce fait les problèmes de datasources JNDI et autres accès aux queues JMS
sont automatiquement résolus par le fait d'injecter une connexion normale
en lieu et place du datasource JNDI par exemple.
Ou encore de tester votre couche métier avec une pseudo-implémentation
de votre couche d'accès aux données.
Cependant il est nécessaire de faire des tests d'intégration sans avoir recours à un serveur d'application, par exemple :
- Les contextes issus des fichiers de configurations de Spring.
- Tester toute l'application et notamment l'interfaçage des différents composants.
Par ailleurs les performances de vos tests peuvent rapidement devenir très mauvaises si vous devez par exemple charger tout vos objets Hibernate avant chaque test unitaire.
De plus un autre problème commun provient du fait que les tests
qui modifient la base de données rentrent souvent en conflits.
Pour résoudre cela, il suffit que vos tests
unitaires étendent AbstractTransactionalSpringContextTests.
De ce fait un rollback ne surviendra qu'à la fin du processus de test.
Et donc les données sur la base ne seront pas corrompues par les tests.
Cela permet par exemple de développer sans devoir remettre constamment
la base de données dans un état stable après chaque bug corrigé.
Plus fort, les tests peuvent s'enchainer s'ils sont interdépendants et
le rollback peut survenir uniquement à la fin.
Naturellement les transactions internes au service à tester seront démarrées
sous forme de transactions incluses (nested).
De plus étendre AbstractTransactionalDataSourceSpringContextTests
vous permet d'utiliser le membre jdbcTemplate qui
donne la possibilité d'interroger l'état
de la base de données dans vos tests.
Voici un exemple de test à l'aide de Spring:
import org.springframework.test.AbstractTransactionalDataSourceSpringContextTests;
public class TestTests extends AbstractTransactionalDataSourceSpringContextTests {
/**
* @see org.springframework.test.AbstractDependencyInjectionSpringContextTests#getConfigLocations()
*/
protected String[] getConfigLocations() {
return new String[] {"/WEB-INF/application-context.xml",
"anotherConfigFile.xml"};
}
public void testService () {
int state1 = jdbcTemplate.queryForInt("SELECT COUNT(*) FROM STOCK");
assert state1 == 2
: "La base de données n'est pas dans un état cohérent pour les tests";
//Test du service : Rajoute 1 article dans le stock
int state2 = jdbcTemplate.queryForInt("SELECT COUNT(*) FROM STOCK");
assert state2 == 3 : "Le test a échoué";
}
}Et enfin (et surtout) Spring, de par l'injection de dépendance, offre la possibilité
d'utiliser des "mock objects" pour simuler une source de données par exemple.
Ce qui permet de faire les tests de non régression sans accès à la base de données ou
encore sans recourir à la couche d'accès aux données.
Voyons un exemple:
class MockStockDao implement IStockDao{
/* Mock members */
Integer qty;
public setQty(Boolean pQty) {
this.qty = pQty;
}
public getQty() {
return this.qty;
}
boolean articleExist(String pArticleId){
return qty > 0 ? true : false;
}
void sortArticleDuStock(String pArticleId, int pQty){
qty = qty - pQty;
}
}Ici nous simulons le StockService. Comme notre "Mock object" implémente StockService
il suffit de fournir une pseudo-implémentation grâce à des données configurées dans le fichier
de configuration de Spring.
J'insiste sur le fait que programmer à l'aide de mock et d'interfaces permet vraiment de paralléliser
le travail et d'améliorer la productivité et la qualité.
Dans le fichier de configuration l'utilisation de notre "mock object" se traduira par:
<?xml version="1.0" encoding="UTF-8"?>
<beans>
<bean id="stockDao" class="MockStockDao">
</bean>
<bean id="stockBusiness" class="StockBusiness">
<property name="dao">
<ref local="stockDao"/>
</property>
</bean>
</beans>Lorsque l'on compare cette configuration à celle donnée précédemment :
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE beans PUBLIC "-//SPRING//DTD BEAN//EN"
"http://www.springframework.org/dtd/spring-beans.dtd">
<beans>
<bean id="prodDataSource"
class="org.apache.commons.dbcp.BasicDataSource">
<property name="driverClassName">
<value>org.postgresql.Driver</value>
</property>
<property name="url">
<value>jdbc:postgresql://localhost:5432/prod</value>
</property>
<property name="username"><value>prod</value></property>
<property name="password"><value>toto</value></property>
</bean>
<bean id="stockDao" class="StockDao">
<property name="dataSource">
<ref local="prodDataSource"/>
</property>
</bean>
<bean id="stockBusiness" class="StockBusiness">
<property name="dao">
<ref local="stockDao"/>
</property>
</bean>
</beans>Nous pouvons nous passer de datasource et d'implémentation effective du Dao sans pour autant changer le code client puisque return mDao.articleExist(pArticleId); continuera à fonctionner.
VI-c. Intégration d'autres frameworks et technologies (IoC, Template)▲
Une des grandes forces de Spring vient du fait qu'il ne vous oblige pas à changer de
framework à tout prix et à tout réapprendre.
Dans cette optique Spring contient un
grand nombre d'utilitaires pour vous faciliter la vie lors de l'utilisation
de vos frameworks préférés.
VI-c-1. Struts▲
2 solutions s'offrent à vous pour intégrer Struts avec Spring :
- Utiliser Spring pour gérer vos actions à l'aide ContextLoaderPlugin et déclarer leurs dépendances dans le fichier de définition de Spring (spring.xml)
- Redéfinir le support d'actions Spring et accéder aux beans de Spring grâce à la méthode getWebApplicationContext().
VI-c-1-a. ContextLoader Plugin▲
ContextLoaderPlugin est un plugin Struts compatible avec la version 1.1 et supérieures qui charge le fichier de configuration de Spring grâce à l'Action Servlet de Struts.
L'extrait suivant doit être intégré dans le fichier struts-config.xml
<plug-in className="org.springframework.web.struts.ContextLoaderPlugIn">
<set-property property="contextConfigLocation"
value="/WEB-INF/action-servlet.xml.xml,/WEB-INF/applicationContext.xml"/>
</plug-in>Ceci fait vous pouvez configurer les actions pour qu'elles soient gérées par Spring. Pour ce faire deux méthodes:
- Surcharger le DefaultRequestProcessor par le DelegatingRequestProcessor de Spring.
- Dans le fichier struts-config.xml, dans la définition d'une action au lieu de définir le type de l'action comme étendant MonAction, utiliser le type DelegatingActionProxy
VI-c-1-a-i. Delegating request processor▲
Pour implémenter cette solution, il suffit de remplacer le contrôleur de Struts par défaut par le contrôleur de Spring, pour ce faire ajouter les lignes suivantes dans le fichier struts-config.xml
<controller>
<set-property property="processorClass"
value="org.springframework.web.struts.DelegatingRequestProcessor"/>
</controller>Chaque action sera, au moment de son appel, résolue dans la liste de beans de Spring. Par exemple:
<action path="/user" type="com.company.web.struts.action.MonAction"/>Provoquera la recherche d'un bean nommé "user". A ce propos spécifier le type n'est pas nécessaire puisque la création de l'objet se fera grâce à Spring. Ce qui nous donnera dans le fichier de configuration de Spring:
<bean id="/user" class="com.company.web.struts.action.MonAction" >
<property name="basicDataService">
.....
</property>
</bean>Remarques:
- Si vous utilisez le mécanisme des modules, le nom du bean (id) devra être précédé dans le fichier de configuration de Spring du nom du module. Par exemple si mon module s'appelle admin: "/admin/user"
- Si vous utilisez tiles vous devez utiliser le DelegatingTilesRequestProcessor
VI-c-1-a-ii. DelegatingActionProxy▲
Dans le cas où vous utilisez déjà un RequestProcessor personnalisé et donc si vous ne pouvez pas utiliser la première méthode vous pouvez passer par la méthode dite DelegatingActionProxy. Pour ce faire il faudra simplement au lieu de préciser le nom de la classe de l'action dans l'attribut type préciser org.springframework.web.struts.DelegatingActionProxy. Voici un exemple:
<action path="/user" type="org.springframework.web.struts.DelegatingActionProxy"
name="userForm" scope="request" validate="false" parameter="method">
<forward name="list" path="/userList.jsp"/>
<forward name="edit" path="/userForm.jsp"/>
</action>Et dans le fichier configuration de Spring:
<bean name="/user" singleton="false" autowire="byName"
class="com.company.web.struts.action.MonAction">
<property name="basicDataService">
.....
</property>
</bean>VI-c-b. Classes ActionSupport▲
L'autre solution est d'étendre les classes d'actions de Spring au lieu d'étendre celle de Struts. Et de ce fait l'action aura un accès direct au conteneur.
public class MonAction extends DispatchActionSupport {
public ActionForward execute(ActionMapping mapping,
ActionForm form,
HttpServletRequest request,
HttpServletResponse response)
throws Exception {
WebApplicationContext ctx = getWebApplicationContext();
ServiceManager mgr = (ServiceManager) ctx.getBean("ServiceManager");
.....
return mapping.findForward("success");
}
}Il existe des classes actions de Spring pour chaque type de classes actions de Struts:
Les deux méthodes sont simples d'utilisation, personnellement la première me semble
plus dans l'optique de Spring.
L'objectif est simplement de pouvoir utiliser l'injection
de dépendances dans vos actions Struts.
VI-c-2. Hibernate▲
Hibernate est très fortement intégré à Spring. Spring va notamment permettre de gérer les transactions au niveau métier (traité un peu plus tard) et d'épargner beaucoup de code par l'intermédiaire du patron de conception template.
Hibernate se configure entièrement dans le fichier de configuration de Spring. Voyons un exemple:
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource">
<property name="driverClassName">
<value>oracle.jdbc.driver.OracleDriver</value>
</property>
<property name="url">
<value>jdbc:oracle:thin:@localhost:1521:test</value>
</property>
<property name="username">
<value>usr</value>
</property>
<property name="password">
<value>pwd</value>
</property>
</bean>
<bean id="sessionFactoryBean"
class="org.springframework.orm.hibernate.LocalSessionFactoryBean">
<property name="dataSource">
<ref bean="dataSource" />
</property>
<property name="hibernateProperties">
<props>
<prop key="hibernate.dialect">
net.sf.hibernate.dialect.OracleDialect
</prop>
<prop key="hibernate.show_sql">true</prop>
<prop key="hibernate.cglib.use_reflection_optimizer">false</prop>
</props>
</property>
<property name="mappingResources">
<list>
<value>com/company/app/dal/hibernate/mapping/Employee.hbm.xml</value>
<value>com/company/app/dal/hibernate/mapping/Codes.hbm.xml</value>
</list>
</property>
</bean>
<bean id="basicDataDao" class="com.company.app.dal.impl.BasicDataDaoImpl">
<property name="sessionFactory">
<ref bean="sessionFactoryBean" />
</property>
</bean>Premièrement on configure un bean qui servira de source de données. Puis on injecte ce bean dans la sessionFactoryBean qui va configurer la couche d'accès gérée par Hibernate. Si l'on regarde de plus près la définition et qu'on la compare à une configuration standard d'Hibernate on remarque de suite les similitudes. Et enfin dans le troisième bean on injecte la session factory ainsi obtenue dans un DAO qui a pour seule particularité d'étendre HibernateDaoSupport.
public class BasicDataDaoImpl extends HibernateDaoSupport
implements IBasicDataDao {
/**
* delete an employee according to its id
*/
public void deleteEmployee(String pEmployeeId) {
List l=getHibernateTemplate().find(
"from EmployeeDto e where e.employeeId='"+pEmployeeId+"'");
if(l.size()>0){
EmployeeDto ret=(EmployeeDto)l.get(0);
getHibernateTemplate().delete(ret);
}
}
}Dans cet exemple on voit la puissance et la simplicité d'usage. Il suffit d'utiliser la méthode getHibernateTemplate() qui permet très simplement d'effectuer des recherches, sauver un objet ou encore le mettre à jour. Tout cela sans avoir besoin de récupérer la session, de la fermer ou encore de gérer les exceptions. De plus toute la gestion des transactions est externalisée dans le fichier de configuration.
Voici le code équivalent sans utiliser Spring:
public class BasicDataDaoImpl implements IBasicDataDao {
/**
* delete an employee according to its id
*/
public void deleteEmployee(String pEmployeeId) {
TODO:complete this
tx=session.beginTransaction();
try{
List l=session.find("from EmployeeDto e where e.employeeId='"
+pEmployeeId+"'");
if(l.size()>0){
EmployeeDto ret=(EmployeeDto)l.get(0);
session.delete(ret);
}
tx.commit();
}catch(Exceptiom e){
}
}
}Par défaut si rien n'est défini la méthode appelée par le template (getHibernateTemplate()) fera un commit en sortant ou un rollback en cas d'exception.
VI-c-3. JDBC▲
De la même façon les appels JDBC sont très fortement simplifiés par l'utilisation de Spring. En fait le gain en ligne de code est encore supérieur à celui apporté par le template hibernate. Pour un exemple se référer au chapitre VII.
VI-c-4. Quartz▲
Quartz est une sorte de crontab pour Java, c'est à dire qu'il permet de planifier des tâches
à effectuer. Par exemple, si vous souhaitez lancer un job toutes les 10 minutes ou une fois par jour à
20h32 précise.
Dans ce cas Spring ne permet pas d'économiser des lignes de code mais permet tout simplement d'intégrer le
pattern IoC dans les jobs Quartz.
Pour mettre en oeuvre Quartz sous Spring, rien de plus simple: il suffit que votre Job étende la classe QuartzJobBean
<bean name="myJob" class="org.springframework.scheduling.quartz.JobDetailBean">
<property name="jobClass" value="com.company.jobs.MyJob"/>
<property name="jobDataAsMap">
<map>
<entry key="myValue" value="2"/>
</map>
</property>
</bean>Par défaut le nom du Job sera égal au nom du bean, c'est à dire dans notre cas myJob. Vous pouvez modifier ce comportement par défaut par l'usage de la propriété name.
La valeur 2 sera injectée au démarrage du job et non simplement à l'instanciation
du bean. Cette différence est très importante et justifie l'usage de la propriété spéciale jobDataAsMap.
Cependant rien ne vous empêche d'utiliser également les mécanismes d'injection normaux pour l'instanciation de l'objet.
package com.company.jobs;
public class MyJob extends QuartzJobBean {
private int myValue;
/**
* Le setter sera appelé par Spring du démarrage de l'objet
* avec la valeur 2
*/
public void setMyValue(int pValue) {
myValue = pValue;
}
protected void executeInternal(JobExecutionContext ctx)
throws JobExecutionException {
// Faire ce que vous avez à faire
}
}Il existe une autre méthode pour définir un job, utiliser MethodInvokingJobDetailFactoryBean.
La différence fondamentale réside dans le fait qu'il ne doit pas s'agir d'un job mais simplement d'un objet métier
qui contient une méthode que l'on aimerait exécuter.
<bean id="myJobDetail" class="org.springframework.scheduling.quartz.MethodInvokingJobDetailFactoryBean">
<property name="targetObject" ref="basicDataService"/>
<property name="targetMethod" value="refresh"/>
</bean>Dans notre exemple, nous définissons le job comme l'exécution de la méthode refresh sur l'objet basicDataService qui est un bean défini ailleurs. Le cas d'utilisation en l'occurrence est simple: obliger une HashMap contenant des codes et textes en diverses langues à se rafraichir selon un rythme prédéfini.
Dans le cas ou vous définiriez deux jobs qui démarrent le même objet métier, il faudra que votre job implémente l'interface Statefull. Pour faire l'équivalent avec la méthode utilisant MethodInvokingJobDetailFactoryBean, il faudra positionner le paramètre concurrent à false.
VII. Java EE sans EJB et sans souffrance (enfin presque, il faut quand même le mériter)▲
VII-1. Transactions au niveau métier (Aspect)▲
Une des fonctionnalités les plus intéressantes est sans doute le support des transactions de façon déclarative, permettant de définir un comportement transactionnel au niveau des objets métiers sans pour autant diminuer la clarté du code. Jusque là, la seule façon de parvenir à quelque chose d'équivalent était de recourir aux EJB CMT. En outre, utiliser Spring pour le support des transactions offre quelques autres avantages, parmi lesquels :
- Une API commune pour accéder au support des transactions des différents frameworks sous-jacents tels que JTA, JDBC, Hibernate, JDO ou encore iBatis.
- Une utilisation simplifiée par rapport à ces APIs.
- Et enfin du fait du premier avantage (API commune) il est possible de tester le code à l'extérieur du serveur d'application et de simplement changer le fichier de configuration lorsque l'on désire profiter de la puissance de celui-ci.
Dans cet article nous nous concentrerons sur le support des transactions déclaratives, l'utilisation des transactions de façon " programmative " étant relativement similaire et plus simple. Celle-ci présente avantages et inconvénients : - Plus invasif que le support déclaratif, ce qui implique que le code intègre des librairies Spring pour fonctionner. + Mais il est plus simple de comprendre où commence et fini la transaction puisqu'il ne faut pas aller faire d'aller-retour entre le fichier Java et le fichier XML.
Un bon compromis est l'utilisation des annotations, qui permettent d'utiliser la méthode déclarative sans pour autant découpler le code Java du comportement de Spring. Cela permet d'éviter les allers-retours entre les classes Java et les fichiers de configuration de Spring.
Voyons comment cela fonctionne. Spring est en fait une implémentation de divers " design patterns " et paradigmes. Parmi les plus connus citons IoC, AOP, Template. C'est grâce au paradigme AOP que Spring va pouvoir effectuer cette tâche.
Le statut d'une transaction est lié à une tâche (thread) d'exécution.
Puisqu'un exemple vaut mieux qu'un long discours, prenons le service suivant:
public interface IStockService {
void sortArticleDuStock(String pArticleId, int pQty)
throws ArticleNotFoundException,
QtyNegativeException,
NotEnoughArticleInStockException;
}
public class StockService implements IStockService {
/**
* L'instance du dao sera injecté par Spring
* lors de l'initialisation du service.
*/
IStockDAO mStockDao = null;
/**
* @see net.zekey.interfaces.business.IStockService#sortArticleDuStock(java.lang.String, int)
*/
public void sortArticleDuStock(String pArticleId, int pQty)
throws ArticleNotFoundException,
QtyNegativeException,
NotEnoughArticleInStockException {
// Si la quantité est négative le service échoue.
if(pQty<0){
throw new QtyNegativeException();
}
//Test si l'article existe dans la base de données
if(!mStockDao.articleExist(pArticleId)){
throw new ArticleNotFoundException();
}
Logger.getLogger(this.getClass()).info("Nombre d'article ["
+ pArticleId + "] : " + mStockDao.getQtyEnStock(pArticleId));
//Sort la quantité du stock.
mStockDao.sortArticleDuStock( pArticleId, pQty);
Logger.getLogger(this.getClass()).info("Nombre d'article ["
+ pArticleId + "] : " + mStockDao.getQtyEnStock(pArticleId));
/*
* Naturellement ce test devrait être fait avant de sortir l'article
* du stock. Faire ce test à cet endroit permet de tester que la
* transaction est bien annulée en cas d'exception.
*/
if(mStockDao.getQtyEnStock(pArticleId) < pQty){
Logger.getLogger(this.getClass()).info("Pas suffisament d'articles" +
" en stock. Lance une exception.");
throw new NotEnoughArticleInStockException();
}
}
/**
* @see net.zekey.interfaces.business.IStockService#getQtyEnStock(java.lang.String)
*/
public int getQtyEnStock(String pArticleId) throws ArticleNotFoundException {
if(!mStockDao.articleExist(pArticleId)){
throw new ArticleNotFoundException();
}
return mStockDao.getQtyEnStock(pArticleId);
}
/**
* @return Retourne le stockDao
*/
public IStockDAO getStockDao() {
return mStockDao;
}
/**
* @param pStockDao Définie le stockDao.
*/
public void setStockDao(IStockDAO pStockDao) {
mStockDao = pStockDao;
}
}Tout d'abord nous commençons par définir le contrat (interface) de notre service, remarquez que la méthode peut renvoyer 3 exceptions en cas de problème. Ces exceptions pourront être utilisées pour agir sur le comportement de la transaction comme par exemple effectuer un commit ou un rollback.
public interface IStockDao{
void sortArticleDuStock(String pArticleId, int pQty);
boolean ArticleExist(String pArticleId);
}
public class StockDAO extends JdbcTemplate implements IStockDAO {
/**
* @see net.zekey.interfaces.dao.IStockDAO#sortArticleDuStock(java.lang.String, int)
*/
public void sortArticleDuStock(String pArticleId, int pQty) {
String sql = "UPDATE articles SET qty = (qty - " + pQty + ") WHERE " +
" article_id = '" + pArticleId + "'";
execute(sql);
}
}La complexité n'est pas plus au rendez-vous sur la couche d'accès aux données. Le DAO exécute une requête SQL et renvoi la réponse dans le cas de la première méthode et exécute une mise à jour dans le cas de la seconde. Si le code semble si simple c'est parce que nous avons eu recours à la classe JdbcDaoSupport de Spring qui fait tout le travail d'ouverture de la connexion, de gestion des exceptions et de fermeture des divers objets. Le code s'en trouve de fait grandement simplifié. Soulignons que la classe JdbcTemplate est thread-safe ce qui est très important pour les connections à la base de données afin que le gestionnaire de transaction s'y retrouve.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE beans PUBLIC "-//SPRING//DTD BEAN//EN"
"http://www.springframework.org/dtd/spring-beans.dtd">
<beans>
<!-- La source de données ou le pool de connexion -->
<bean id="prodDataSource" class="org.apache.commons.dbcp.BasicDataSource">
<property name="driverClassName">
<value>org.apache.derby.jdbc.EmbeddedDriver</value>
</property>
<property name="url">
<value>jdbc:derby:derbyDB;create=true</value>
</property>
<property name="username"><value>user1</value></property>
<property name="password"><value>user1</value></property>
</bean>
<!-- L'implémentation de la couche d'access aux données -->
<bean id="stockDao" class="net.zekey.dao.StockDAO">
<property name="dataSource">
<ref local="prodDataSource"/>
</property>
</bean>
<!-- L'implémentation de la couche métier -->
<bean id="stockServiceTarget" class="net.zekey.business.StockService">
<property name="stockDao">
<ref local="stockDao"/>
</property>
</bean>
<!-- Le gestionnaire de transactions -->
<bean id="prodDataSourceTrxManager"
class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource">
<ref local="prodDataSource" />
</property>
</bean>
<!-- Notre proxy vers le service métier avec support des transactions -->
<bean id="stockService"
class="org.springframework.transaction.interceptor.TransactionProxyFactoryBean">
<property name="transactionManager">
<ref local="prodDataSourceTrxManager" />
</property>
<property name="target">
<ref local="stockServiceTarget" />
</property>
<property name="transactionAttributes">
<props>
<prop key="articleExist">PROPAGATION_REQUIRED, readOnly</prop>
<prop key="sortArticleDuStock">PROPAGATION_REQUIRED,
-net.zekey.business.exceptions.ArticleNotFoundExeception,
-net.zekey.business.exceptions.QtyNegativeException,
-net.zekey.business.exceptions.NotEnoughArticleInStockException
</prop>
</props>
</property>
</bean>
</beans>Passons maintenant à la partie la plus intéressante. Le coeur de la bête : le fichier de configuration.
Dans un premier temps nous déclarons une source données (datasource), pour faciliter les choses elle est locale mais pourrait très bien être contenue dans votre serveur d'application et disponible via JNDI. L'exemple peut donc être adapté très facilement si vous utilisez une autre base de données, les propriétés définies pouvant être externalisées dans un autre fichier de propriétés.
Puis nous décrivons l'objet stockDao, comme il étend la classe JdbcTemplate, l'objet possède un mutateur (setter) setDataSource qui est utilisé par le mécanisme de template pour effectuer tout le travail de gestion de la connexion. Spring va donc instancier cet objet puis y injecter la source de données.
Ensuite vient la description de l'objet métier, qui de la même façon, se voit injecter l'objet (bean) créé précédemment. Petite subtilité : le nom de cet objet n'est pas stockBusiness comme on pourrait s'y attendre mais stockBusinessTarget. L'explication viendra immédiatement quand l'on regardera la dernière partie. Avant la définition du proxy, nous déclarons un gestionnaire de transactions. Il peut être de différents types : JDBC, Hibernate, JTA etc… selon vos besoins.
En dernier lieu, nous créons le service lui-même. Pour ce faire et parce que nous voulons le support des transactions de manière déclarative (sinon nous aurions pu nous arrêter à la définition précédente) nous définissons un objet de type TransactionProxyFactoryBean. Ceci créera un proxy vers l'objet (bean) cible (target), en l'occurrence stockBusinessTarget. De ce fait chaque appel aux méthodes citées (articleExist, sortArticleDuStock) dans la propriété transactionAttributes sera intercepté, traité et redirigé vers la méthode correspondante du service.
La première propriété définie est le gestionnaire de transactions (transactionManager). Elle a pour paramètre la source de données (dataSource). C'est logique puisque le gestionnaire de transactions doit savoir sur quelle connexion opérer les commits et rollbacks.
Le deuxième paramètre spécifie la cible du proxy, c'est-à-dire stockBusinessTarget. Cela signifie que cette classe servira de cible au proxy.
Et enfin la dernière propriété définit les méthodes à rendre transactionnelles ainsi que leur comportement. C'est certainement la partie la plus intéressante :
Dans le premier cas on définit qu'une transaction est nécessaire (PROPAGATION_REQUIRED) pour exécuter cette méthode mais que cette transaction est en lecture seule. En effet cela permet de s'assurer dans un traitement donné, que la base de données ne sera pas affectée. Remarquez la propriété key qui vaut articleExist. Il s'agit ni plus ni moins que du nom de la méthode. Ce nom peut être exprimé sous la forme d'une expression régulière, par exemple article*
Dans le second cas, une transaction est également requise, elle n'est pas en lecture seule et en plus effectuera un rollback si la méthode renvoie une exception de type QtyNegativeException, ArticleNotFoundExeception ou une RuntimeException.
D'une façon générale le comportement est le suivant : Un commit à toujours lieu sauf en cas de RuntimeException, c'est-à-dire par exemple en cas d'erreur SQL. Toutes les exceptions SQL, de gestion de la connexion et plus généralement les exceptions techniques seront embarquées dans une RuntimeException.
A noter qu'un + QtyNegativeException en lieu et place du - QtyNegativeException indiquera que l'on souhaite effectuer un commit si cette exception est renvoyée. A noter que notre exemple fonctionnerait aussi bien avec Hibernate ou JDO moyennant quelques changements mineurs, notamment le transaction manager qui dans le cas d'Hibernate se devra d'être un HibernateTransactionManager et non pas un DataSourceTransactionManager. Si l'utilisation de JTA devient nécessaire (par exemple pour pouvoir effectuer des commit/rollback sur plusieurs sources de données) il faudra recourir au JtaTransactionManager.
Voici la syntaxe générale de déclaration d'une transaction
:PROPAGATION_NAME, ISOLATION_NAME, readOnly, timeout_NNNN, +Exception1, -Exception2
Seule la première partie est obligatoire (propagation).
- PROPAGATION_NAME: Constante qui définit le comportement de la transaction par rapport à une transaction de niveau supérieur.
- PROPAGATION_MANDATORY: Continue dans la transaction courante, renvoie une exception si aucune transaction n'est présente.
- PROPAGATION_NEVER: Effectue le traitement de façon non-transactionnelle. Renvoie une exception si exécuté dans une transaction.
- PROPAGATION_NOT_SUPPORTED: Effectue le traitement de façon non-transactionnelle. Suspend la transaction pendant l'exécution de la méthode.
- PROPAGATION_REQUIRED: dans la transaction courante, en crée une nouvelle si aucune n'existe.
- PROPAGATION_REQUIRES_NEW: crée une nouvelle transaction et suspend la transaction actuelle s'il en existe une.
- PROPAGATION_SUPPORTS: Continue dans la transaction actuelle, effectue le traitement de façon non-transactionnel si aucune transaction n'est présente.
- PROPAGATION_NESTED : Crée une nouvelle transaction dans la transaction courante ou en crée une nouvelle si aucune n'existe.
ISOLATION_NAME: Spécifie le niveau d'isolation d'une transaction avec les autres transactions.
readOnly: Définit si la transaction est en lecture seule
timeout: Définit le timeout de la transaction, par défaut TIMEOUT_DEFAULT
+Exception1 : La transaction sera " comitée " si cette exception survient.
-Exception2 : La transaction sera " rollbackée " si cette exception survient.
VII-2. Fournir des services à d'autres applications▲
Un service non négligeable des EJB est la capacité d'exposer un objet, c'est-à-dire un EJB en tant que service à d'autres machines virtuelles que celle dans laquelle il a été initialement déployé.
Spring fournit quelque chose d'équivalent cependant soulignons qu'il ne garantit pas le fail-over et la montée en charge que permet un serveur d'application. De plus Spring n'a pas de mécanisme de sécurité intrinsèque et nécessite de lui adjoindre le framework de sécurité acegi.
Pour exposer un service par RMI c'est très simple:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE beans PUBLIC "-//SPRING//DTD BEAN//EN"
"http://www.springframework.org/dtd/spring-beans.dtd">
<beans>
<bean class="org.springframework.remoting.rmi.RmiServiceExporter">
<!-- does not necessarily have to be the same name as the bean to be exported -->
<property name="serviceName" value="StockService"/>
<property name="service" ref="stockService"/>
<property name="serviceInterface" value="net.zekey.interface.business.IStockService"/>
<property name="registryPort" value="1009"/>
</bean>
</beans>Voilà notre service est disponible pour d'autres JVM. Pour l'utiliser il faudra
l'interface métier, un fichier de configuration et Spring, naturellement.
Voici à quoi le fichier de configuration ressemble:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE beans PUBLIC "-//SPRING//DTD BEAN//EN"
"http://www.springframework.org/dtd/spring-beans.dtd">
<beans>
<bean id="stockService" class="org.springframework.remoting.rmi.RmiProxyFactoryBean">
<property name="serviceUrl" value="rmi://localhost:1009/StockService"/>
<property name="serviceInterface" value="net.zekey.interface.business.IStockService"/>
</bean>
</beans>Il suffira alors de demander au conteneur le bean qui s'appelle "stockService".
VIII. Je veux mes EJB !▲
Naturellement il reste toujours des domaines d'application très
précis dans lesquels
l'utilisation des EJB est la plus adaptée, voire la seule possibilité.
Voyons ensemble quelques un de ces cas:
- Dans le cas d'une architecture distribuée horizontalement. C'est à dire qu'il y a par exemple 3 serveurs web pour la présentation et 4 serveurs d'application contenant des EJB. Attention il ne faut pas confondre architecture distribuée et clustering.
- Si vous devez maintenir une application existante.
- Et la meilleur de toute, votre direction vous a intimé l'ordre d'utiliser les EJB parce que quelqu'un a lu quelque part que c'était la meilleure solution.
Dans ces différents cas de figure il est intéressant de pouvoir utiliser Spring dans les EJB. Cela vous permettra par exemple d'externaliser la partie métier et d'utiliser les EJB comme relai vers la couche métier. Et donc de ce fait de rendre votre application bien plus testable puisque l'on pourra utiliser Spring pour injecter la source de données ou encore les objets d'accès à la couche de données, ce qui permettra bien sûr d'utiliser des objets mocks.
VIII-1. Implémentation des EJB grâce à Spring (Methode 1)▲
Voyons un exemple concret d'implémentation d'un EJB session sans état (stateless).
Cette implémentation utilise XDoclet pour générer descripteurs, classes et interfaces
requises par la norme EJB.
/**
* XDoclet-based session bean. The class must be declared
* public according to the EJB specification.
*
* To generate the EJB related files to this EJB:
* - Add Standard EJB module to XDoclet project properties
* - Customize XDoclet configuration for your appserver
* - Run XDoclet
*
* Below are the xdoclet-related tags needed for this EJB.
*
* @ejb.bean name="My"
* display-name="Name for My"
* description="Description for My"
* jndi-name="ejb/My"
* type="Stateless"
* view-type="both"
*/
public class MyBean implements SessionBean {
/** The session context */
private SessionContext context;
/**
*
*/
public MyBean() {
}
/**
* @see javax.ejb.SessionBean#ejbActivate()
*/
public void ejbActivate() throws EJBException, RemoteException {
}
/**
* @see javax.ejb.SessionBean#ejbPassivate()
*/
public void ejbPassivate() throws EJBException, RemoteException {
}
/**
* @see javax.ejb.SessionBean#ejbRemove()
*/
public void ejbRemove() throws EJBException, RemoteException {
// TODO Auto-generated method stub
}
/**
* Set the associated session context. The container calls this method
* after the instance creation.
*
* The enterprise bean instance should store the reference to the context
* object in an instance variable.
*
* This method is called with no transaction context.
*
* @throws EJBException Thrown if method fails due to system-level error.
*/
public void setSessionContext(SessionContext newContext)
throws EJBException {
context = newContext;
}
/**
* An example business method
*
* @ejb.interface-method view-type = "both"
*
* @throws EJBException Thrown if method fails due to system-level error.
*/
public void businessMethod() throws EJBException {
//Put your business code here
}
}On remarque tout de suite que la proportion de code à usage purement
technique, c'est à dire la gestion de l'EJB, est bien plus importante que
la partie métier.
Il s'agit là d'un des plus gros problèmes des EJB, ils sont
extrêmement volubiles.
De plus ils sont difficilement testables en isolation. Ce qui de fait
viole pas mal de bonnes pratiques en vigueur. Que faire pour y remédier?
- Factoriser et externaliser le code de gestion de l'EJB.
- Externaliser le code métier dans un POJO.
- Utiliser l'injection de dépendance pour faire tout cela proprement.
Pour réduire la quantité de code, on peut utiliser la classe AbstractStatelessSessionBean de Spring. Ce qui réduira tout ce code à
/**
* XDoclet-based session bean. The class must be declared
* public according to the EJB specification.
*
* @ejb.bean name="MyEJBTest"
* display-name="EJB to remotly access Spring bean"
* description="Description for MyBean"
* jndi-name="MyRemote"
* local-jndi-name="MyLocal"
* type="Stateless"
* transaction-type="Container"
* view-type="both"
*
* @ejb.home extends="javax.ejb.EJBHome"
* local-extends="javax.ejb.EJBLocalHome"
*
* @ejb.interface extends="javax.ejb.EJBObject"
* local-extends="javax.ejb.EJBLocalObject"
*
*
*/
public class MyBean extends AbstractStatelessSessionBean implements Business{
TheBusinessPOJO pojo;
/**
*
*/
private static final long serialVersionUID = 9138189234567975625L;
public void setSessionContext(SessionContext sessionContext) {
super.setSessionContext(sessionContext);
// make sure there will be the only one Spring application context
setBeanFactoryLocator(ContextSingletonBeanFactoryLocator.getInstance());
setBeanFactoryLocatorKey("businessBeanFactory");
}
public void onEjbCreate() throws CreateException {
pojo = (TheBusinessPOJO) getBeanFactory().getBean("businessPOJO");
}
/**
* An example business method
*
* @throws EJBException Thrown if method fails due to system-level error.
*/
public String executeBusinessMethod(){
return pojo.executeBusinessMethod();
}
}Analysons cela:
* @ejb.home extends="javax.ejb.EJBHome"
* local-extends="javax.ejb.EJBLocalHome"
*
* @ejb.interface extends="javax.ejb.EJBObject"
* local-extends="javax.ejb.EJBLocalObject"Ces directives Xdoclet ont été rajoutées, la classe n'implémentant plus l'interface SessionBean directement (mais par héritage) Xdoclet ne sait plus générer les interfaces et les classes home correctement.
public void setSessionContext(SessionContext sessionContext) {
super.setSessionContext(sessionContext);
// make sure there will be the only one Spring application context
setBeanFactoryLocator(ContextSingletonBeanFactoryLocator.getInstance());
setBeanFactoryLocatorKey("businessBeanFactory");
}
public void onEjbCreate() throws CreateException {
pojo = (TheBusinessPOJO) getBeanFactory().getBean("businessPOJO");
}En premier lieu on fixe le contexte, puis on définit une BeanFactoryLocator ainsi que
son nom. Par défaut Spring cherchera un fichier nommé beanRefContext.xml dans le classpath
et tentera de résoudre le nom dans la clé (businessBeanFactory) afin de trouver la position
du fichier de configuration.
En second lieu lors de la création de l'EJB on initialisera le POJO contenant la méthode
métier à exécuter.
De cette façon vous pourrez tester la logique en dehors du conteneur à l'aide mock objects
par exemple.
Voici un exemple de fichier beanRefContext.xml:
<!DOCTYPE beans PUBLIC "-//SPRING//DTD BEAN//EN"
"http://www.springframework.org/dtd/spring-beans.dtd">
<beans>
<bean id="businessBeanFactory"
class="org.springframework.context.support.ClassPathXmlApplicationContext">
<constructor-arg value="applicationContext.xml" />
</bean>
</beans>Dans cet exemple la configuration (le fichier servant à définir les beans) sera applicationContext.xml et devra se trouver dans le classpath.
VIII-2. Implémentation des EJB grâce à Spring (Methode 2)▲
La deuxième méthode consiste à garder les EJB tel quel et à chercher un contexte d'application:
...
public abstract class AbstractSessionBean implements SessionBean {
/** This beans session context */
private SessionContext sessionContext;
/** This beans appliction context */
protected ApplicationContext applicationContext =
ApplicationContextFactory.get().getApplicationContext();
...
}La classe ApplicationContextFactory étant définie comme suit:
public class ApplicationContextFactory {
/** The configuration file for the service application context */
private final static String[] FILE_NAMES_CONFIGURATION =
{ "service-beans.xml", "datasource.xml" };
/** The singleton */
private final static ApplicationContextFactory instance =
new ApplicationContextFactory();
/** Gets the singleton of this class */
public static ApplicationContextFactory get() {
return instance;
}
/** The service bean factory instance */
private ApplicationContext applicationContext = null;
/**
* Gets the service bean factory instance
* @return Said bean factory
*/
public synchronized ApplicationContext getApplicationContext() {
if (this.applicationContext == null) {
this.applicationContext = new ClassPathXmlApplicationContext(
FILE_NAMES_CONFIGURATION
);
}
return this.applicationContext;
}
}Dès lors il sera possible d'utiliser les EJB comme
adaptateurs techniques pour les services Spring. Permettant d'utiliser la
sécurité et la gestion des transactions du conteneur si désiré.
Voici un exemple d'utilisation:
public class MonBean extends AbstractSessionBean {
/**
* An example business method
*
* @throws EJBException Thrown if method fails due to system-level error.
*/
public String executeBusinessMethod(){
return (TheBusinessPOJO) applicationContext.getBean("businessPOJO").executeBusinessMethod();
}
}VIII-3. Utilisation des EJB grâce à Spring▲
Spring vous permet de facilemt utiliser un EJB aussi bien
distant que local.
Dans les deux cas il suffit de définir l'EJB dans le fichier de configuration
pour pouvoir l'utiliser simplement en le demandant à la
bean factory.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE beans PUBLIC "-//SPRING//DTD BEAN//EN"
"http://www.springframework.org/dtd/spring-beans.dtd">
<beans>
REMOTE JNDI CONNECTION
<bean id="remoteJndiConnection"
class="org.springframework.jndi.JndiTemplate">
<property name="environment">
<props>
<prop key="java.naming.factory.initial">
weblogic.jndi.WLInitialContextFactory
</prop>
<prop key="java.naming.provider.url">t3://localhost:7001</prop>
</props>
</property>
</bean>
<bean name="MyEJB"
class="org.springframework.ejb.access.SimpleRemoteStatelessSessionProxyFactoryBean">
<property name="jndiName"><value>MyRemote</value></property>
<property name="resourceRef"><value>false</value></property>
<property name="businessInterface">
<value>com.ipt.springejb.business.ejb.Business</value></property>
<property name="jndiTemplate">
<ref bean="remoteJndiConnection"/>
</property>
</bean>
</beans>Pour pouvoir utiliser un EJB distant il faut d'abord définir un contexte JNDI,
c'est la définition remoteJndiConnection qui s'en charge en définissant
notamment le port et la machine où se trouve le serveur JNDI ainsi que la
factory.
Après il ne reste plus qu'a donner le nom JNDI de l'EJB ainsi que de son
interface pour pouvoir l'utiliser comme un vulgaire POJO.
IX. Tips & tricks▲
IX-A. Spring et les fichiers de propriétés▲
Lorsque l'application grandit, souvent le nombre de configurations devient impressionnant.
Au lieu d'avoir les différentes valeurs dissimulées dans différents fichiers,
il suffit de toutes les mettre dans un seul fichier de configuration.
<bean id="propertyPlaceholderConfigurer" class="org.springframework.beans.factory.config.PropertyPlaceholderConfigurer">
<property name="locations">
<list>
<value>/WEB-INF/classes/example.properties</value>
</list>
</property>
<property name="ignoreUnresolvablePlaceholders"><value>true</value></property>
</bean>
<bean id="dataSource" class="com.example.DataSource">
<property name="username"><value>${database.user}</value></property>
</bean>Et dans le fichier de propriétés.
database.user=steveX. Conclusion▲
Nous avons vu ensemble un certain nombre de concepts inhérents à Spring,
ainsi que leurs implémentations.
Nous avons également prouvé que Spring est structurant et qu'il améliore
de façon significative la productivité et la maintenabilité des applications.
Il n'y a pas là d'invention géniale mais plutôt un ensemble cohérent qui,
bien que puissant, est simple et relativement intuitif à mettre en oeuvre.
XI. Liens utiles▲
- Sous-Forum Spring sur developpez.com
- Introduction au framework Spring
- Spring 2.0 et namespaces
- Gestion d'authentification et d'autorisation avec ACEGI Security
- Tutoriel Spring IOC
- Construction d'une application MVC distribuée avec Spring Remoting
- Construction d'une application swing MVC à trois couches avec Spring
- Spring MVC par l'exemple - partie 1
- Test unitaire avec Spring
- CRUD avec Spring, JSF et Hibernate